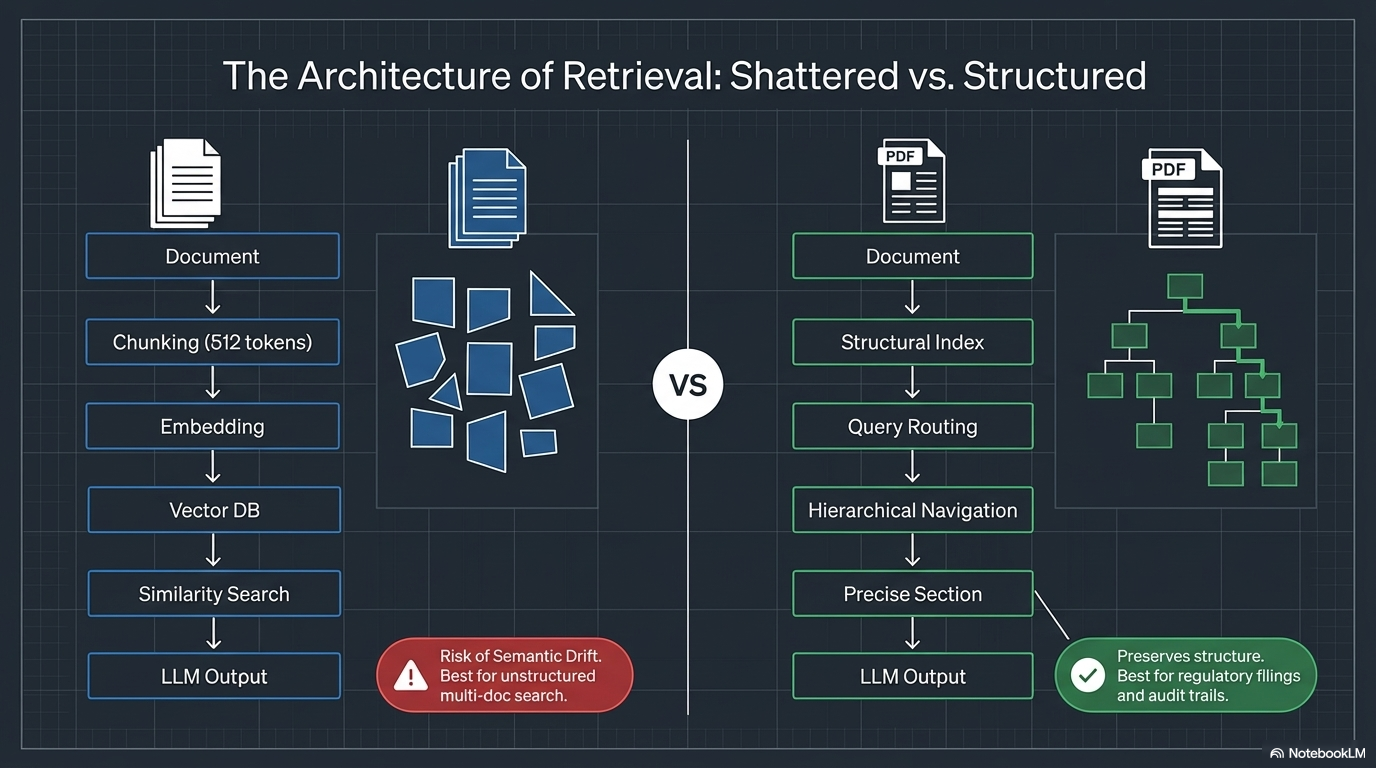
Everyone building with RAG today starts with the same playbook: chunk the document, embed the chunks, run a similarity search, feed the top results to an LLM. It works. Until it doesn’t.
The moment you point traditional Vector RAG at a 200-page regulatory filing, a credit policy manual, or a Basel III framework document, something breaks. Not the model — the retrieval. The system returns passages that sound right but are structurally wrong. A paragraph from an appendix instead of the actual policy section. A board reporting clause instead of the due diligence requirement you asked for.
This is the problem Vectorless RAG solves. And it is not what most people think it is.
The Core Problem: Semantic Similarity Is Not Structural Relevance
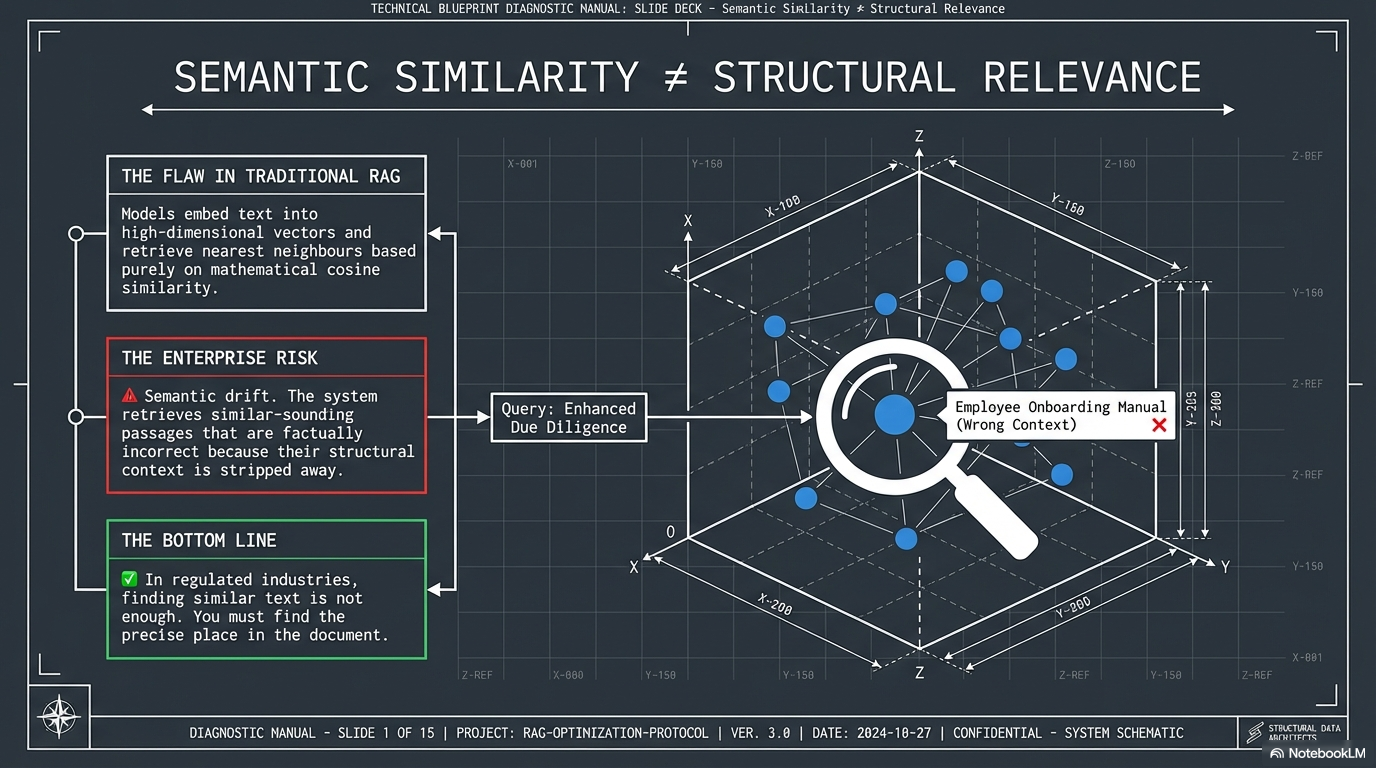
Traditional RAG models embed text into high-dimensional vectors and retrieve nearest neighbours based purely on mathematical cosine similarity. The enterprise risk is semantic drift — the system retrieves similar-sounding passages that are factually incorrect because their structural context has been stripped away.
In regulated industries, finding similar text is not enough. You must find the precise place in the document.
Vectorless RAG Is Not Just GraphRAG
One of the most common misconceptions: people hear “vectorless” and immediately think GraphRAG. GraphRAG is real, it is production-ready, and it is valuable — but it is one branch of a much larger family.
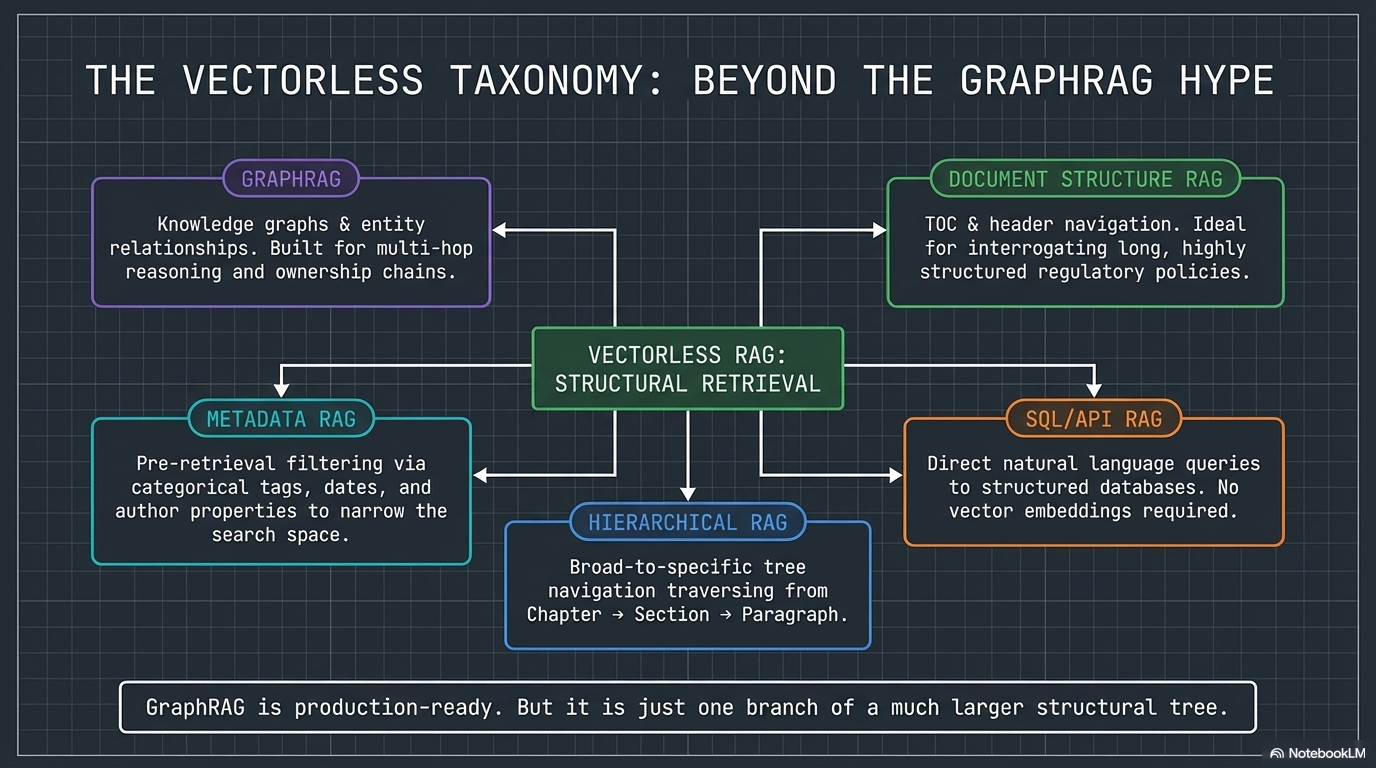
The vectorless RAG family includes five distinct approaches:
- Document Structure RAG — Navigates tables of contents, headers, and sections to locate answers in long, structured documents
- Hierarchical RAG — Tree-based navigation that moves from broad to specific: Chapter → Section → Paragraph → Answer
- GraphRAG — Knowledge graphs that map entity relationships. Excellent for multi-hop reasoning, ownership chains, and counterparty risk
- Metadata RAG — Pre-filters the search space using tags, dates, authors, or categories before retrieval begins
- SQL/API RAG — Queries structured databases or APIs directly. No embeddings needed
Each solves a different retrieval problem. The architecture should match the document, not the trend.
How the Two Approaches Actually Work
The difference is architectural, not incremental.
Traditional Vector RAG takes a document, chops it into 512–1024 token fragments, encodes those fragments into high-dimensional vectors, stores them in a vector database (Pinecone, Weaviate, Chroma), and runs a similarity search — cosine distance or dot product — to find the “Top-K” nearest neighbours. The LLM then generates an answer from those chunks.
The problem: chunking destroys hierarchical relationships. A compliance framework’s numbered sections, cross-references, and procedural logic get flattened into disconnected text fragments. The retrieval finds what sounds similar, not what is structurally correct.
Vectorless RAG takes a different path entirely. It builds a structural index — a document tree based on the table of contents, headers, and section hierarchy. When a query comes in, an LLM reasons over that tree structure, routes the query to the right branch, and navigates hierarchically (Chapter → Section → Paragraph) to retrieve the precise section with full context. Every answer comes with a structural path — an audit trail.
Vector RAG finds similar text. Vectorless RAG finds the right place.
The Numbers: A 67.7% Accuracy Gap
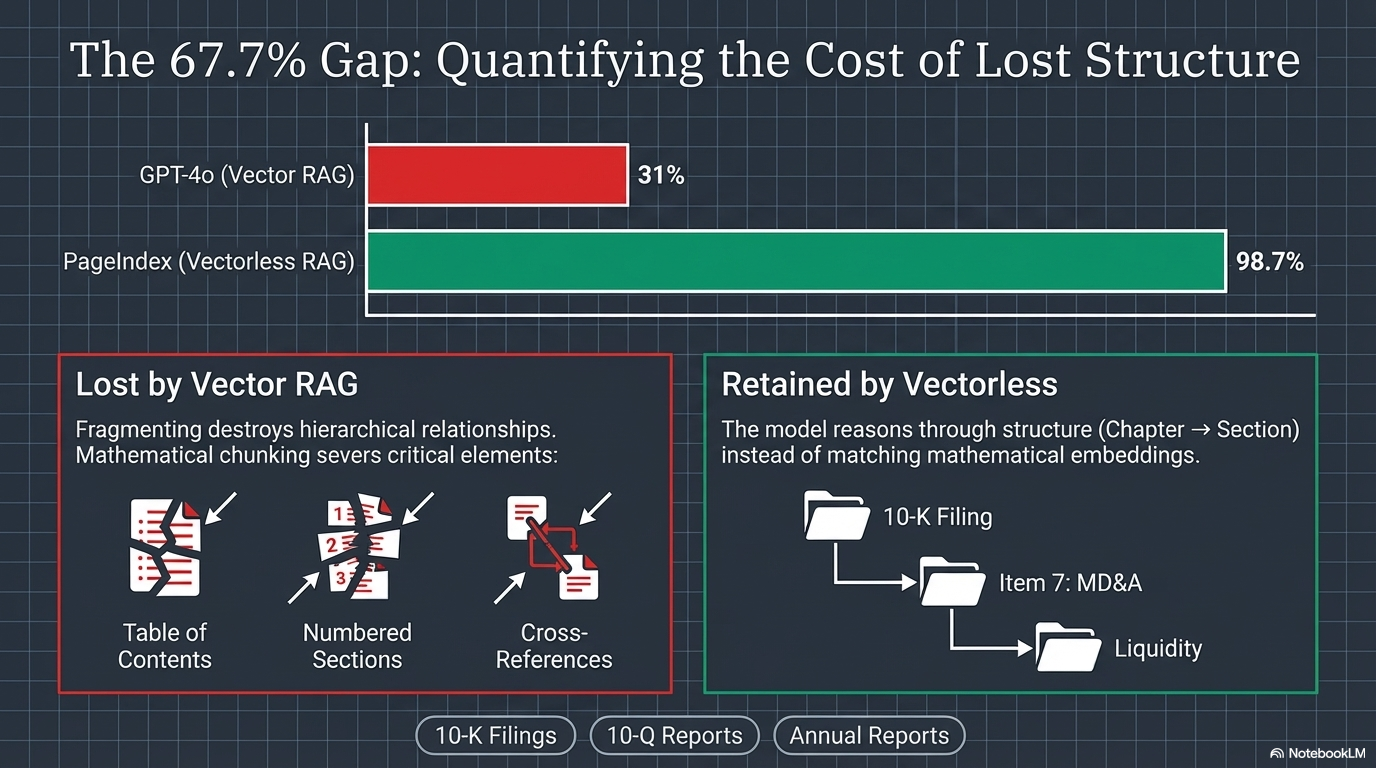
On the FinanceBench benchmark for financial documents, PageIndex (a vectorless RAG engine) achieved 98.7% accuracy. GPT-4o with traditional vector RAG scored approximately 31%.
That is not a marginal improvement. That is a fundamentally different architecture producing fundamentally different results on structured documents.
What Vector RAG loses through fragmentation — table of contents structure, numbered sections, cross-references — Vectorless RAG retains by reasoning through structure (Chapter → Section) instead of matching mathematical embeddings.
The Operational Impact

The 67.7% gap is not a mathematical quirk. It is the operational difference between a failed audit and examiner-ready compliance. Consider three dimensions:
Context Preservation — Vector RAG returns isolated fragments where surrounding procedural logic is severed. Vectorless RAG returns the exact, complete section bounded by its original hierarchical headers.
Cross-Reference Handling — Vector RAG is blind to external references (e.g., “See Appendix B”). Context is permanently lost. Vectorless RAG preserves intact cross-references, allowing secondary retrieval of related policies and definitions.
Audit Trail Capability — Vector RAG provides no definitive source location; manual human verification is strictly required. Vectorless RAG automatically generates examiner-ready citations (e.g., “Source: AML Policy v3.2, Section 4.3.2”).
Where This Matters Most: Banking and Regulated Industries
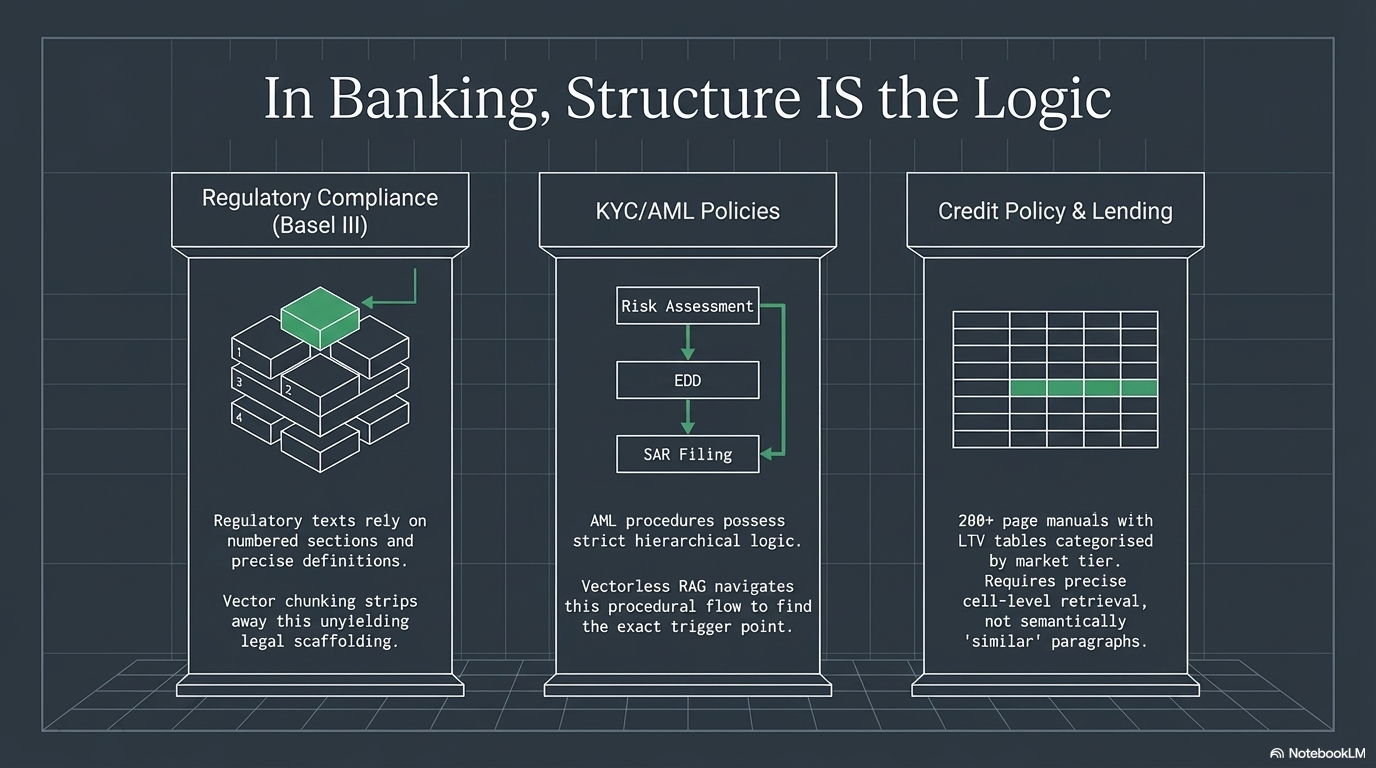
Vectorless RAG is not interesting because it is new. It is interesting because certain documents demand it. Banking, healthcare, and legal are built on deeply structured texts where precision and traceability are not optional.
Regulatory Compliance
Frameworks like Basel III, MiFID II, and Dodd-Frank are deeply structured — numbered sections, defined terms, precise cross-references. When a compliance officer asks “What are the capital adequacy requirements under Pillar 1?”, they need Section 3.2.1. Not a semantically similar paragraph from the appendix.
Vectorless RAG navigates the document tree and returns the exact section with an audit trail.
KYC/AML Policy Documents
Anti-money laundering procedures have strict hierarchical logic: Customer Risk Assessment → Enhanced Due Diligence → Suspicious Activity Reporting → Escalation Protocols. The structure is the logic. Chunking and embedding destroys the procedural flow.
When an analyst asks “What triggers Enhanced Due Diligence for a Politically Exposed Person?”, Document Structure RAG navigates: AML Policy → Customer Risk → PEP Classification → EDD Triggers → exact answer. Vector RAG might pull a chunk from the board reporting section simply because it mentions “PEPs.”
Credit Policy and Lending Guidelines
A loan officer asking “What is the maximum LTV for commercial real estate in Tier 2 markets?” needs the exact policy cell from a 200-page manual. Hierarchical RAG navigates directly: Credit Policy → Commercial RE → Tier 2 Markets → LTV Table → answer.
Financial Reports and Earnings Filings
10-Ks, 10-Qs, and annual reports are standardized, structured documents. This is exactly the domain where vectorless approaches dominate — and where the FinanceBench numbers come from.
Audit and Examination Trails
Regulators do not accept “the AI found a semantically similar chunk.” They need: “The answer came from Section 4.3.2, Paragraph 3 of the Basel III framework, dated December 2023.” Vectorless RAG provides this traceability by design. Vector RAG does not.
A Real-World Scenario: EDD Requirements for PEPs
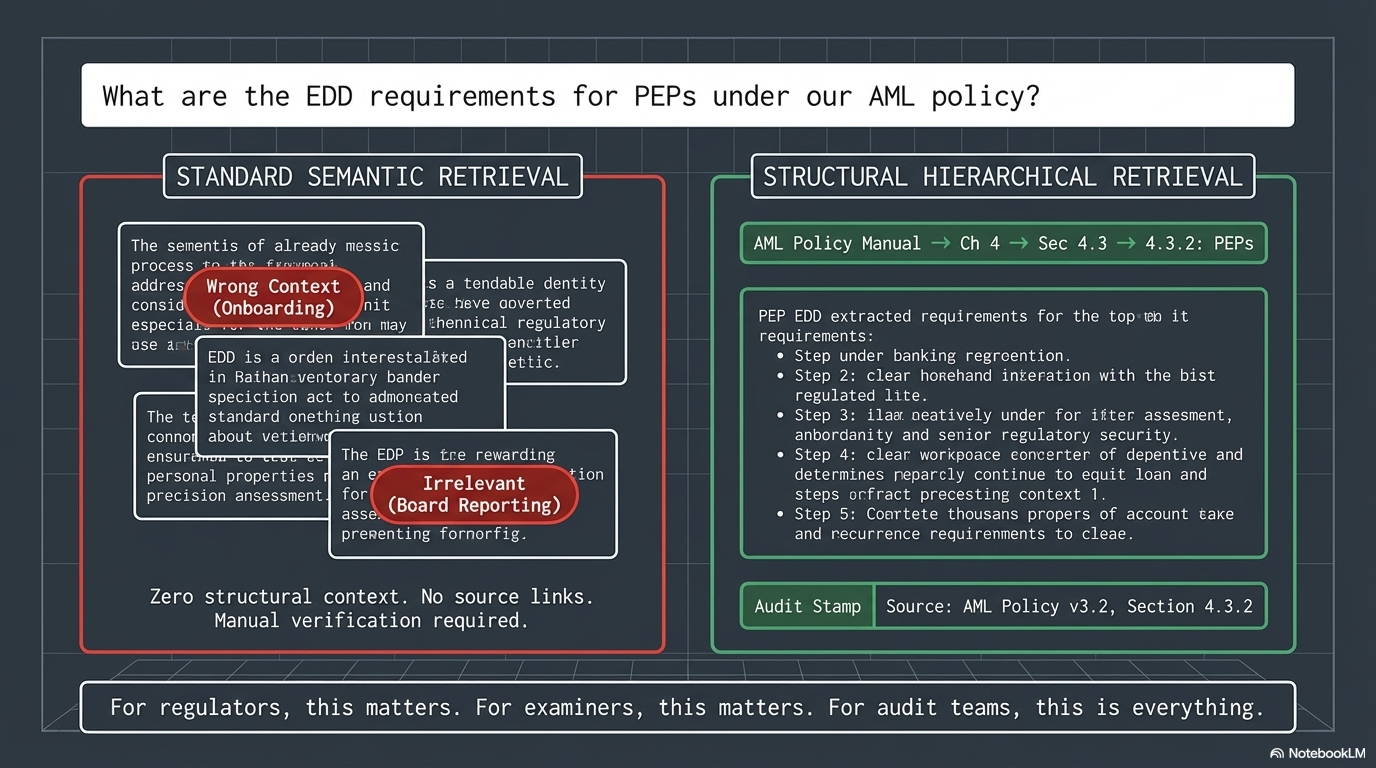
A compliance analyst asks the AI assistant: “What are the enhanced due diligence requirements for politically exposed persons under our AML policy?”
With Vector RAG:
- Returns 5 chunks from various sections that mention “due diligence” or “PEP”
- One chunk is from the customer onboarding section (wrong context)
- Another is from the board reporting section (mentions PEPs but not EDD requirements)
- The analyst has to manually verify which chunks are actually relevant
- No audit trail. No structural context
With Vectorless RAG:
- Navigates: AML Policy Manual → Chapter 4: Customer Due Diligence → Section 4.3: Enhanced Due Diligence → 4.3.2: Politically Exposed Persons
- Returns the exact section with all sub-requirements intact
- Preserves cross-references to related sections (4.1: Risk Categories, 5.2: SAR Filing)
- Full audit trail: “Answer sourced from AML Policy v3.2, Section 4.3.2, last updated Jan 2026”
For regulators, examiners, and audit teams, this is the difference that matters.
The Core Architecture Diagnostic Matrix

Understanding when to use each approach starts with understanding what each one actually does:
| Vector RAG | Vectorless RAG | GraphRAG | |
|---|---|---|---|
| Core Mechanism | Similarity Search (Cosine) | Document Tree Navigation | Multi-hop Knowledge Graph |
| Primary Risk | Semantic Drift (Incorrect context) | Depends on document structure quality | High compute and build cost |
| Ideal Documents | Scattered, Unstructured (Emails, Chats) | Long, Structured (Manuals, Filings) | Highly Relational (Ownership Chains) |
| Search Modality | Broad Document Recall | Precise Section Retrieval | Entity Dependency Mapping |
| Enterprise Use Case | Support Tickets and Discovery | Compliance, Audit, and Credit Policy | Counterparty Risk and Due Diligence |
The Hybrid RAG Ecosystem
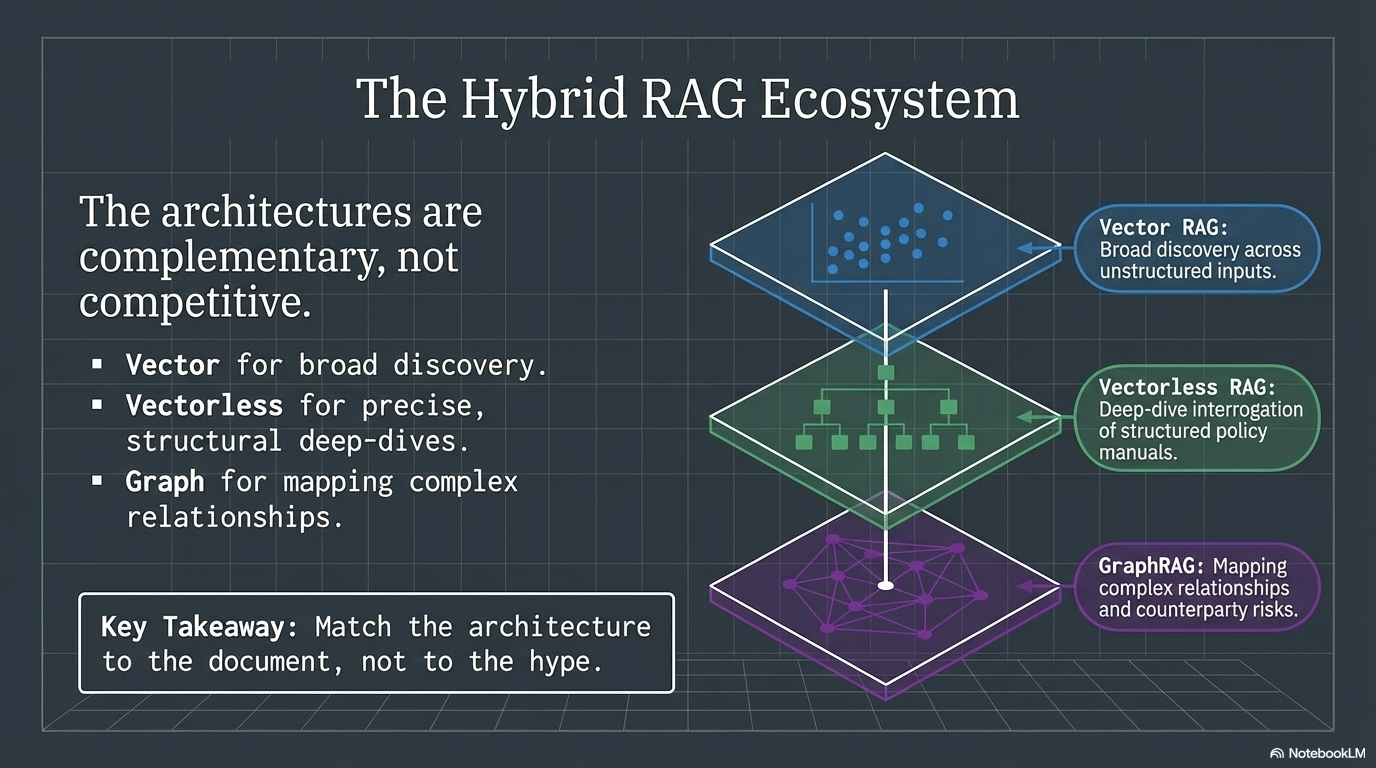
Neither approach is universally better. The trade-offs are real:
Vector RAG’s risk is semantic drift. It returns passages that sound similar but are factually wrong in context. In banking, “similar” is not good enough when the wrong section could mean a compliance violation.
Vectorless RAG’s risk is structural dependency. Its effectiveness depends entirely on document structure quality. If a document is poorly organized — no clear headers, no consistent hierarchy — tree navigation breaks down.
The emerging pattern in enterprise RAG is hybrid:
- Vector for broad discovery across unstructured inputs
- Vectorless for deep-dive interrogation of structured policy manuals
- Graph for mapping complex relationships and counterparty risks
The architectures are complementary, not competitive.
Choosing the Right Approach
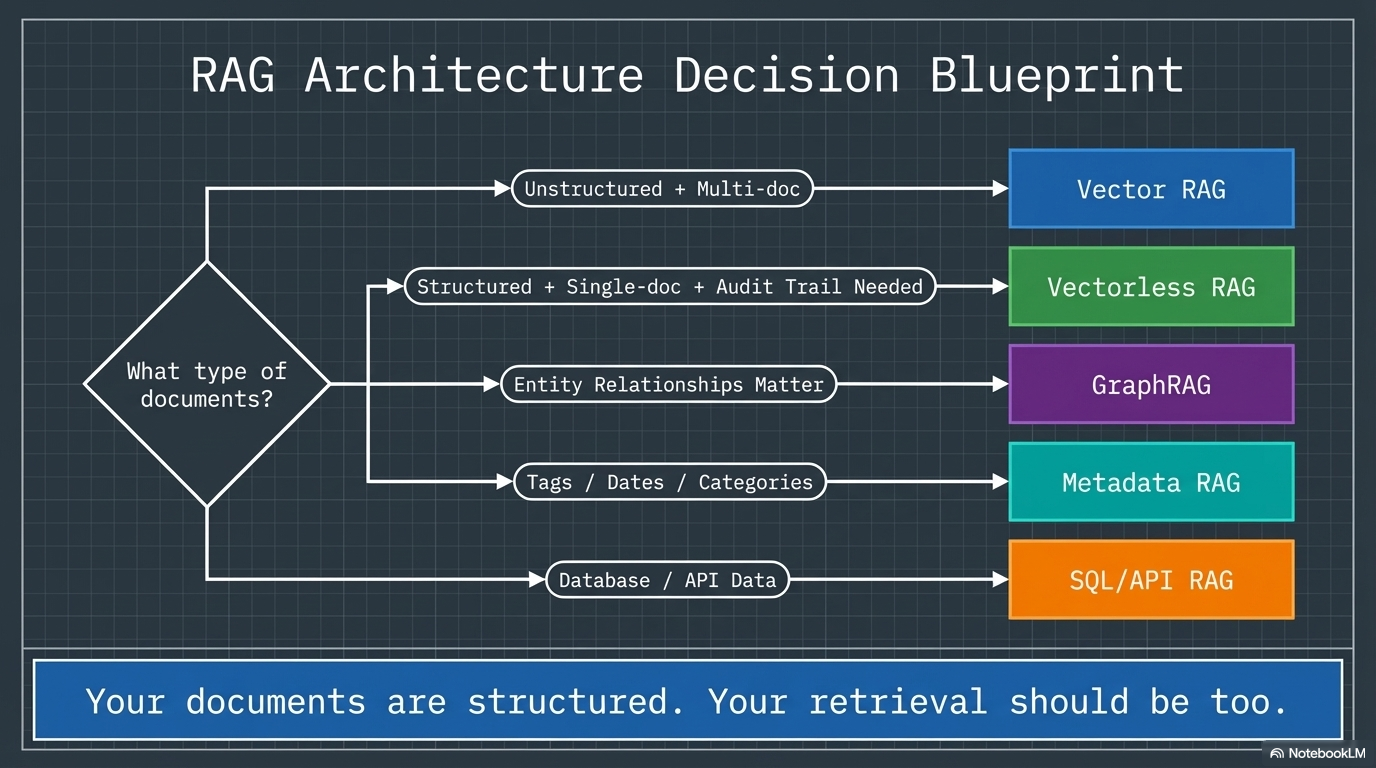
The decision framework is straightforward:
Use Vector RAG when you are searching across many unrelated documents, your content is unstructured (emails, chat logs, support tickets), you need broad recall, or you are working with a multi-document corpus with diverse topics.
Use Vectorless RAG when you are working with long, structured documents (regulatory filings, policy manuals, legal contracts), precision retrieval with an audit trail is required, hierarchical navigation matches the document’s logic, or compliance demands traceable answers.
Use GraphRAG when you need multi-hop reasoning across entity relationships, you are mapping ownership chains, beneficial ownership, or counterparty risk, or your queries are entity-centric (people, organizations, transactions).
Use Hybrid when you need broad search and precise retrieval in the same system. Vector for discovery, vectorless for deep-dive. This is where enterprise RAG is heading.
The Bottom Line
Vector RAG finds similar text. Vectorless RAG finds the right place. GraphRAG finds relationships.
They are not competitors. They are complementary. The question is not “which is better?” — it is “which matches your document architecture?”
In banking, the documents are structured. The retrieval should be too.
Your documents are structured. Your retrieval should be too.
References:
- PageIndex (vectorless RAG engine): pageindex.ai
- FinanceBench benchmark: 98.7% accuracy (vectorless) vs ~31% (vector RAG with GPT-4o)
- Microsoft GraphRAG: microsoft.github.io/graphrag
If this perspective on RAG architecture was useful or you have thoughts on how you are approaching retrieval in your organization, feel free to reach out. These are exactly the kinds of technical conversations I enjoy having.